Lab Exercise #2: Correlation, Regression and Modeling of Population and Population Density with nighttime imagery provided by the DMSP OLS satellite.
Background
In this lab you
will perform analyses and use data associated with my dissertation: Census
From Heaven: Estimation of Human Population Parameters using Nighttime
Satellite Imagery. The datasets provided include: the world,
In the world directory you have two coverages and one Grid: A point coverage of world cities with population attribute for about 2,000 of them, a country boundaries coverage with various aggregate national statistics as attributes, and a low-gain DMSP OLS composite image of the earth at night. All of these are in the dreaded Goode’s Interrupted Homolosine Projection, which is a strange coverage not supported by ArcView or Arc/INFO explicitly but you can read and analyze the data anyway.
The unitedstates
directory contains one coverage and four Grids. Usalazea is a coverage of the
The LosAngeles
directory has a subdirectory with Tiger files of
Technical history of the DMSP
OLS platform and related imagery
The Defense Meteorological Satellite Program’s Operational
Linescan System (DMSP OLS) platform was designed as a meteorological satellite
for the United States Air Force. The DMSP system consists of two
sun-synchronous polar orbiting satellites at an average elevation of 865
kilometers above the earth. The swath width of a typical DMSP image is 3,000
kilometers. One satellite observes the earth at dawn and dusk, the second
observes the earth at approximately noon and midnight. The sensor on the system
has two bands: a panchromatic visible-near infrared (VNIR) band and a thermal
infrared band. Nighttime imagery provided by the DMSP OLS has been available
since the early 1970's. The DMSP sensors are more than four orders of magnitude
more sensitive to visible-near-infrared radiances than traditional satellite
sensors optimized for daytime observation. However, the high sensitivity of the
sensor was not implemented to see city lights. It was implemented to see
reflected lunar radiation from the clouds of the earth at night. The
variability of lunar intensity as a function of the lunar cycle is one of the
reasons why the satellite system’s sensors were designed with such a large
sensitivity range. As you will see later, this proved to be very fortuitous for
studies of intra-urban population density.
The digital archive of the DMSP OLS data is housed at the
These earlier datasets are referred to as the ‘high-gain’
data product. Two kinds of high-gain data are used in this research. The first
kind of high-gain data has the value of the pixel representing a percentage of
times light was measured relative to the number of cloud free orbits for which
that pixel was sampled. For example, if observed light levels were 20, 60, 0,
and 40 for four observations from four orbits, the value in the pixel would be
75, representing light observation for 75% of the orbits. The second kind or type of high-gain data
simply used the maximum light level observed in a given pixel for those cloud
free orbits (in the case of the previous example the value would be 60). Only
the maximum light level data could be interpreted as a measure of observed
light intensity. The primary drawback of these data was the issue of saturated
pixels in urban areas. Both high-gain datasets were virtually binary with
mostly black or dark pixels valued at 0 and brightly lit ‘urban’ pixels with a
value of 63 (the DMSP sensor has a six-bit quantization). These data lent
themselves to aggregate estimation of urban ‘cluster’ populations but were not
good at estimating population density variation within the urban clusters. This
drawback was identified and resulted in a special request to the Air Force
regarding the use of the DMSP OLS platform.
As mentioned before, the DMSP OLS platform was designed to observe reflected lunar radiation at night (primarily reflected from clouds). During the days just prior to and after a new moon there is very little lunar radiation striking the earth. Consequently, the sensor has its gain set to its maximum possible value. The NGDC requested that the Air Force turn down the gain on several orbits near the new moon. This request was honored by the Air Force and resulted in what is now referred to as the ‘low-gain’ data product. Turning down the gain produced dramatic results with respect to the saturation of the ‘urban’ pixels. The low-gain data show dramatic variation of light intensity within the urban areas, and it can easily be calibrated to at-sensor radiances. Hyper-temporal datasets similar to the previous data were made using the low-gain orbits. This research utilizes both the ‘high-gain’ and ‘low-gain’ DMSP data.
Outline of your tasks/objectives
First
you will look at the global datasets and try to build a model that estimates
the population of the cities based solely on manipulations of the nighttime
image. Then, you will try to improve that model by incorporating aggregate
national statistics. Second you will apply a similar model to the
Analysis of World data
Most of you have probably seen the nighttime imagery from the DMSP OLS. (If you haven’t you will soon.) Explore the global image of nighttime lights with country boundaries, city points, etc. It may seem obvious that the lights represent population. However, building a mathematical model derived from the lights to represent population is not as easy as it looks.
Task #1: Using Arc/INFO and/or ArcView create a polygon coverage that has every contiguous blob of light in the nighttime image (to do this you will need to create a binary grid from the ‘earthatnight’ grid using the CON function in Grid). Next you will have to do a REGIONGROUP command in Grid. Next a GRIDPOLY command so you have a coverage of polygons that represents all the urban clusters in the world as identified by the nighttime imagery. Each of these polygons has a unique ID. Follow the instructions below to complete Task #1:
1. To start Arc, click on the Start button à Programs à ArcInfo à Arc.
2. You
need to set the workspace in Arc to identify the directory that contains the
w I:\username\spatialstats\popandnighttimeimagery\spatialdata\unitedstates
- Type Grid to access the Grid module of ArcInfo.
- To convert the earthatnight grid to binary, at the Grid prompt type:
- citylights = con(earthatnight < 33, 0, 1)
Where citylights is the filename for the new outgrid, earthatnight is the grid provided containing the lights data, 33 is the threshold value for which any value less than or equal to 33 will become a 0 in the new binary outgrid and any value over 33 will become a 1. In the new binary grid, 1 indicates lit and 0 indicates dark.
- To classify each individual cluster with a unique value type:
- lights = regiongroup(citylights, out tab, EIGHT, WITHIN, #, NOLINK)
Where lights is the new outgrid name, citylights is the binary grid that was just created, out tab is the new VAT table created with the unique identifiers, EIGHT and WITHIN are parameters to choose how the pixels are clustered, # is a space holder for a parameter not chosen and NOLINK allows processing to be faster as there will be no link with the previous VAT since it is not necessary to keep the binary numbers.
- To convert the grid to a coverage type:
- earthlights = gridpoly(lights)
Where ‘earthlights’ is the new coverage name and lights is the cluster grid made above.
Task #2: Right now the polygon coverage you have does not have any attributes other than an ID. You will need it to have the following attributes: AREA, COUNTRY (preferably a FIPS code), GDP/Capita of Country, # of cities with known population that fall inside polygon, the names of these cities as one long string, and the sum of the population of these cities. (Sometimes, due to conurbation, more than one city falls into these polygons.) Follow the instructions below to create the table in Task #2:
- Open ArcView
- Add the earthlights coverage to the view
- Open the earthlights table
- Click start editing and delete any records with –9999 (no data) values.
- Click the View window and the select button and click on the hemisphere polygons while holding down the shift key. Then go back to the table window and delete the highlighted records. The remaining records should be just the cities.
- Convert the remaining records to a shapefile.
- To do a spatial join between the earthlights shapefile and the world cities point coverage:
- Open both in ArcView
- Select extensions under the file menu and choose the geoprocessing extension
- Under the View menu click geoprocessing wizard and choose the spatial join button.
- Click next and choose the world cities shapefile and the new earthlights shapefile
- Click Finish. The data from both shapefiles will now be in the worldcities shapefile table.
- To join the GNP data to the country coverage:
- In ArcView, click on the project window and open the project menu, select add table.
- Add the excel table containing the GNP data.
- Click on the country fields of both tables and then click the Table menu and Join to join the data together in the two tables by country.
- Click the file menu and the export button, choose delimited text and export the table.
Task #3: Open the table in JMP IN 4 to then perform the statistical analysis. Answer the following questions:
Question 1: Run a simple linear regression between area and total population for each of the cities in the table. Describe the results and problems.
Instructions: To run the linear regression in JMP, have the table open and choose Analysis à Fit Y by X. Choose PopMetro as the Y column and Area as the X column. Click OK. In the new window that pops up choose fit mean and fit line to generate the statistics.
Question 2: Transform your area and total population values to Ln(Area) and Ln(total population) and run the regression again. Describe the results and problems.
Instructions: Create a new column by choosing the Cols menu à new column. Give the new column an appropriate name such as poparea. Choose numerical and continuous data types. Under the new property button, choose formula à scroll down and choose the area column à choose the transcendental pull-down menu à choose log10 to get the log of area column. This will produce a new column of log values in the table. Repeat these steps with the popmetro column to get logpopmetro.
Question 3: Color code your points so that points representing cities in countries with a GDP/capita less than $1,000 / year are red, $1,001-$5,000/year are blue, and over $5,000/year are green. Run the same regression on Ln(area) vs. Ln(total Population). Describe the results.
Instructions: To color code the table according to the scheme described above:
- Select the Rows menu à Row Selection à Select Where; a pop up window opens.
- In this window scroll down and select the GNPPCAP column.
- Then choose “is less than” from the pull down menu and type in 1000 in the space. This will select all the rows where GNP is less than 1000.
- Next, choose colors from the Rows menu and choose a red square.
- Select the Rows menu à Row Selection à Select Where; a pop up window opens.
- Choose the GNPPCAP column
- Then “is greater than or equal to” from the pull down menu and type in 1001 in the space.
- Choose colors from the Rows menu again and choose a blue square.
- For the last group, repeat steps 1-4, but choose “is greater than” from the pull down menu and type in 5000 and choose a green square from colors.
To run the regression, choose Analyze à Fit Y by X, choose logpop for the y value and logarea for the x value and click OK. Choose fit line and fit mean from the red pull down button on the new window showing the scatter plot.
Question 4: Create a new column in JMP called IncomeClass based on the red, blue, green code above. Run separate regressions on ln(area) vs. Ln(total population) for each class. How do these regressions on subsets of the data compare to the regression on all the data? Describe and explain the difference.
Instructions: To create a new column and populate it with the income information:
- Create a new column by choosing the Cols menu à new column. Name the column IncomeClass, choose numeric and continuous.
- Under New Property, click Formula and a formula window will pop up.
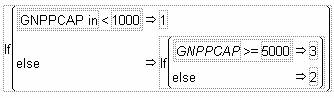
- Under the Functions menu, click conditional à IF. A formula will pop up in the blank area of the window.
- Double click on “expr” in the formula and choose the GNPPCAP column from the Table Columns box.
- Double click on the expr box and type ‘in’ then type a space, a less than sign and 1000 beside GNPPCAP.
- In the then clause box type 1.
- Click on the “else clause” box and then click on Conditional under the Functions menu and choose IF again. This will add a new IF statement to the formula.
- In the new expr box choose the GNPPCAP column, double click on this to be able to type in it, type a space then an “is greater than” sign and right beside that an equals sign, then 5000.
- In the “then clause” box right beside this type 3.
- After the last else statement, choose the “else clause” box and type 2.
To run the regression, choose the Analyze menu à Fit Y by X. Select logpopmetro as the y column and logarea as the x column and click ok. From the red pulldown button on the new window choose Group By and then choose IncomeClass from the window that pops up. Then fit line and fit mean to give you three lines and means for each of the income classes.
Question 5: Assume
you only had the regression knowledge from the previous exercises and you had
to estimate the populations of
a) What would your estimates and 95% confidence intervals be for those cities if you used the global parameters?
b) What would your estimates and 95% confidence intervales be for those cities if you used the regression parameters derived after sub-setting the data to ‘rich’, ‘mid-income’ and ‘poor’?
c) Check the “actual” population figures for those cities and see if they landed inside your 95% confidence intervals.
Instructions: The model from Question 2 is found in the regression window. To refresh your memory, go to Analyze à Fit Y by X and select logpopmetro for the y value, logarea for the x value, click ok then choose fit line and fit mean from the red pull down menu in the new window under Linear Fit. Your regression equation should look like logpopmetro = 1.5654175 + 0.5244921(logarea).
To determine confidence intervals:
- Right click under the Estimate column under the Parameter Estimates section of the statistics in this window.
- Choose columns, then upper 95% and lower 95%. The confidence intervals for both the slope and the intercept will be added to this section.
- You need to find the log area values for the cities in question. Click on the cities column header in the table. Then use Edit à Search à Find and type in the city name in the box. Check the box that says “Restrict to Selected Columns” and then click the Find button. It will look in the cities column and find the city you typed in. Once you have the row the city is located in, scroll over in the table to the logarea column to get the area for that city.
- Plug the area into the logarea portion of the model and calculate the estimated population: logpopmetro = 1.565 + 0.524(logarea for the city) from the above example.
- To calculate the upper and lower limits for the population estimate from the confidence intervals, add or subtract the upper and lower limits to each of the slope and intercept estimates (from the Parameter Estimate section of the regression window) and recalculate the model using these numbers.
- For example, from the above model, the intercept is 1.565 so if the upper 95% confidence interval is 2.229, you would add these together to get the new intercept for the upper limit for the model.
- If the 95% confidence interval for the upper limit for the slope is 0.605, you would add this to 0.524 from above.
- Therefore, the new model for the upper confidence interval would be logpopmetro = 3.794 + 1.129(logarea for the city).
- You would do the same for the lower confidence interval limits.
- The numbers are all log based, so you will have to reverse the log on the answer to get the actual population estimate.
- To get the estimates for the rich, mid-income and poor data, you would use the same process as above except that a separate model for each category will have been produced, so you need to use that particular model as the base for each. You can then compare the population estimates against actual populations from the popmetro column of the table.
Question 6: How could you use these regression models, a nighttime image of the world, and a % urban figure for every nation of the world to estimate the total global population?
Instructions: Believe it or not, but this question requires no further instructions! J Just give some creative ideas of how you would improve the model.
Analysis
of
Task #1: Generate a table similar to the one you did for the world
using the population density and nighttime imagery grids for the
- Start ArcView, select New View, and then click No when asked to add data to the view now.
- Under File on the tool bar, click on Extensions, check Spatial Analyst, and then click OK.
- Click the Add Theme button on the tool bar to add data to the view.
- In the Data Source Type box, click on Grid Data Source.
- Navigate to the lab folder where the Spatial Statistics Data is stored. Under Popandnighttimeimagery, click on the SpatialData folder, and then open the unitedstates folder.
- Add the grids uspopden and usclusterid to your view.
- Click each grid on in the legend to display them.
- Double click on the uspopden theme in the legend to bring up the Legend Editor. Click on Classify and choose natural breaks as the classification method. Click apply, then close the Legend Editor.
- Click on the usclusterid theme in the legend to make it the active theme.
- Under Analysis on the toolbar, click on Summarize Zones. In the Summarize zones dialog box, Uspopden should be theme containing the variable to summarize. Click OK.
- Once the output table of the Summarize Zones process pops up, click on File on the toolbar and choose Export. Export the table as a delimited text file. Save it to your designated area on the server.
- Open JMP IN, click on Open Data Table in JMP IN Starter. Under the Files of Type box choose Text Import Files. Navigate to where your data table was stored, click on your filename, and then click Open.
- If JMP reads all of your column titles into one column, make a note of the order of the string of column headings to re-label each column. Right click on the heading of the column you want to change a column heading, then choose Column Info. This brings up a dialog box where you rename the column.
- In this table, the ClusterID is equal to the Value column, ClusterArea is the Area column, and Cluster Population is in the Sum. To complete the table outlined in Task 1, you need to take the natural log of both the area and the population variables. First create a new column, by clicking on Cols on the task bar and select New Column. Under column heading type Ln(Area), keep the default data type of numeric and continuous. Under New Property, select Formula. Click on Transcendental and choose Log. Click once on Area to enter it into the formula. Click Apply, then OK. Select Next and repeat to create a new column Ln(pop).
- Under File on the tool bar click on save as and save this table as a JMP file.
Question 7: Produce a histogram of the population density
data.
Instructions: To create a histogram in ArcView, click on the uspopden theme in the legend to make it active. Click on the Histogram button on the tool bar.
Question 8: Produce a histogram of the usatnight data
Instructions: In ArcView click on the View box, then click on the Add Theme button on the toolbar. Navigate to the lab folder where the Spatial Statistics Data is stored; add the grid usatnight to your view. Click on the usatnight theme in the legend to make it active, and then click on the Histogram button on the toolbar.
Question 9: By looking at these histograms comment on the likelihood that a model derived from nighttime light emissions could predict population density.
Question
10: Produce a correlogram of the pop density data.
Instructions: To create a correlogram, you must use the CORRELATION command several times. The CORRELATION command in performed in Grid.
1. To start Arc, click on the Start button à Programs à ArcInfo à Arc.
2. You
need to set the workspace in Arc to identify the directory that contains the
w I:\username\spatialstats\popandnighttimeimagery\spatialdata\unitedstates
3. At the Arc prompt, type Grid and hit enter.
4. You will need to run several correlation commands and record the resulting R-value. To create a correlogram you need to plot R2 versus offset. The format for the CORRELATION command in Grid is as follows:
a. CORRELATION gridname1, gridname2, xoffset, yoffset
5. To run a correlation on one grid, uspopden with zero offset, type:
a. CORRELATION uspopden
6. To run a correlation on uspopden type, with an x offset type:
a. CORRELATION uspopden, #, 1
7. Hit the up arrow to repeat your previous command and change the x offset of 1 to a 2 and submit the correlation command. Repeat for x offsets of 3, 4, 5, 10, 25, 50 and 100. Remember to record the resulting R-value.
8. Now run correlations for offsets in the y direction by using the following command:
a. CORRELATION uspopden, #, #, 1
9. Repeat for y offsets of 2, 3, 4, 5, 10, 25, 50, and 100.
10. To plot your correlogram for uspopden, enter your numbers into a data table using JMP IN. Start JMP IN, and choose New Data Table from the JMP IN Starter. Add a new column to for the offset distance. Then add new columns for your R-value for x offsets and another for R for the y offsets.
11. Create a new column to calculate R2, label the column, and then under formula select yx from the “keypad” of mathematical functions. The default is squared so just click on your R variable column, click Apply and then OK to complete the formula. Repeat for the y offset data.
12. Under the Analyze button on the tool bar, select Fit y by X. For the Y response enter your R2 variable for the x offset and for the X factor enter the offset distance. Click OK to get a plot, then click on the red diamond on the Bivariate Fit Bar, and select Fit Each Value to create your correlogram. Repeat using the R 2 for the y offsets.
Question 11: Produce a correlogram of the usatnight data
Instructions: Repeat the processes outlined in question 10 for the grid usatnight.
Question 12: What does the
correlogram of the popdensity data suggest about the effectiveness of a perfect
model if it is mis-registered by one pixel?
Question 13: Run a FOCALMEAN
on the pop density data (use a 5x5 and an 11 x 11 filter). Now generate two new
correlograms for the ‘smoothed’ data. How does FOCALMEAN work, and how does it
change the data?
Instructions:
- To run the FOCALMEAN command with a 5x5 filter, in Grid type the following:
- uspopden5 = FOCALMEAN(uspopden, rectangle, 5, 5)
- To run the FOCALMEAN command with an 11x11 filter, in Grid type the following:
- Uspopden11 = FOCALMEAN(uspopden, rectangle, 11, 11)
- Run correlations for x and y offsets of 0, 1, 2, 3, 4, 5, 10, 25, 50, and 100 and create correlograms following the procedures outlined in question 10.
Question 14: Perform the same
Ln(area) vs. Ln(Population) regression on the
a) How is the regression equation for the
b) Which regression parameters do you think
are more accurate?
c) Does this
Instructions: You will run a regression analysis using the data
table created in Task #1.
- Start JMP IN and choose open data table. Navigate to your directory and read in the JMP file that you created.
- Under the Analyze button on the tool bar select Fit Y by X, choose ln(area) for the X factor and ln(pop) for the Y response, click OK.
- Click on the red diamond on the Bivariate Analysis bar and select Fit Line from the drop down menu.
- To compare to the results for the World Cities, first open your data table from the World Analysis in part 1 of this lab.
- From under Rows on the tool bar, click Row Selection, then Select Where. Choose FIPS CNTRY from the columns. In the first box, select equals and the type US in the second box.
- Create
a table with just the
- Run a regression analysis on the subset of US data. From Analyze on the toolbar, select Fit X by Y. Select ln(area) for your x Factor and ln(area) for your Y response.
Question
15: Use the CORRELATION command in Grid to get a simple correlation coefficient
between the
Instructions:
- To run the correlation between uspopden and usatnight type in the following command:
a. CORRELATION uspopden, usatnight
Question16:
Analysis
of the
If you look at this data for a while you will find that no model that uses nightime lights alone will ever predict population density perfectly. However, this may be because the census data is only a particular kind of representation of population density: e.g. residential population density. It does not account for employment based population density. Suppose you are trying to characterize ‘ambient’ population density that is a temporally averaged measure of population density that accounts for human mobility, employment, entertainment, etc. Without implanting GPS receivers in the heads of a large population and monitoring their spatial behavior it is a very difficult thing to measure this ‘ambient’ population density. A crude approximation might be the average of residence-based population density and employment-based population density.
Question
17: Apply your model of population density prediction from before to the
a) What is the correlation of your
model to residence based population density?
b) What is the correlation of your model to employment based pop. density?
c) What is the correlation of your
model to the average of these two?
Instructions:
- Open a workspace in Arc, type
- w C:\pathname\toallfiles
- At the Arc prompt, type Grid
- At the Grid prompt, type lg to list grids
- You
should have a list that includes Lowgain night image,
- At Grid prompt, type display 9999
- A display window will open. Click in the first window.
- At Grid prompt, type mape LAMSPLG
- At Grid prompt, type image LAMSPLG
- The grid image can be seen in the display window.
- To make the ambient population grid, you must average the values of two grids that already exist: popdensity and jobdensity.
- At Grid prompt, type:
- name = (LAPOPDESITY + LAJOBDENSITY) / 2
- To see the new grid type mape ambi, enter, then type image ambi, enter.
- It’s not easy to tell anything about the image from a black and white display with no reference points. To verify the grid info, you can run correlations on the new grid to the source grids and to itself. The correlation to the source grids should be fairly good, but not exact.
- At the Grid prompt, type:
- correlation ambi nightradcal 0 1
- 1 and 0 will be fine to verify the data in the new Grid. Correlation gives you an R that indicates that the data in each cell are slightly different than the cell next to it.
- Nightradcal is a nighttime light image of LA. To determine the exact nature of the relationaship between the two Grids, create a table in Arc. At the Grid prompt, type:
- ambirad.txt = sample(lanightradcal ambi)
- Open JMP IN and select ambirad.txt to open table. Save the jmp table.
- In JMP IN, go to Analysis à Fit Y by X. Use the Lights as the independent variable (X). Use the Ambi as the predictable variable (Y).
- The regression equation will be visible when the fit line option is executed.
- To use this equation to make a prediction of ambient population density, you must go to Arc and launch Grid. At the Grid prompt type:
- estLA = 168.21918 + 7.8361837 * lanightradcal
- This command builds a grid of the estimated ambient population based on the lights at night using the regression equation.
Question 18: What do your results above suggest regarding your model’s ability to predict ‘ambient’ population density?
Question 19: Visualization of Error: Subtract your model from each of the following: Residence-based pop den, Employment based pop den, and average of Residence and employment based pop den.
a) Which errors look most random?
b) Which ‘map of residuals’ has the smallest mean absolute deviation?
c) Produce correlograms for each of these residual maps.
d) What do these correlograms suggest about these three images?
Instructions: What you want to know now is if the estimate that you just built is any good. So, you check the estimate against the data that you already have. This is also done in Grid. You need to subtract the estimated grid from the data grids rather than the other way around. Where the difference is positive, the estimate is too high, and where it is negative the estimate is too low. Reversing the subtraction equation will, of course, reverse the results.
- To create three new grids that show cell by cell where the estimate is too high or too low when compared with the three sources of data that were used to create it type the following expressions at the Grid prompt:
- estLAambi = estLA – ambi
- estLApop = estLA – popdensity
- estLAjob = estLA – jobdensity
- You need to make correlograms for each of the residual (error) maps that you just created. Type the following expressions at the Grid prompt to generate the R values that you need. Hint: you can do this by using the up-arrow key and changing the offset number in each line.
- correlation estLApop estLApop 0 0
- correlation estLApop estLApop 0 1
- correlation estLApop estLApop 0 2
- correlation estLApop estLApop 0 3
- correlation estLApop estLApop 0 4
- correlation estLApop estLApop 0 5
- correlation estLApop estLApop 0 10
- correlation estLApop estLApop 0 25
- correlation estLApop estLApop 0 100
- Use the correlation command in grid to calculate R and create correlograms for the other residual maps
- Use JMP IN or Excel to build tables of the r2 values from the correlations and display them as correlograms.
- Finally, in ArcView, turn on Spatial Analyst
- Add the grids that were given and those that you have created to the view in order to see what has happened. You should find that the popdensity grid, jobdensity grid, and the ambient grid you created by averaging those two grids are in the workspace that you named at the beginning.
6. From
the regression equation, you created a grid that estimated the population from
the nighttime lights. Add that to the project as a theme.
7. Lastly,
add the three grids that compare the estimate to the data for
jobdensity, popdensity, and ambient density.
8. Save
the project.
9. Of the seven grid themes, the last three
grids show the errors of the estimate. They are the ones that help to analyze
the model. Using legend editor, reclassifiy the maps so that the color
ramps are two-toned and the scheme is standard deviations from the mean. Then,
display the histogram for each Grid.
Remember that over estimated cells are positive and underestimated cells
are negative.
Study
your own city
Pick some city in
the